Shipping a SaaS from my phone
I built Runvault with Claude Code agents doing a lot of the actual typing, often while I wasn't near my laptop.
The hard part was figuring out whether I could trust what they built without being at my desk.
This is the Railway and Cloudflare setup that made that loop work.
The loop I was optimizing for
When agents write most of the code, Verification becomes the bottleneck.
The agent opens a PR. Now I need to know: does this actually work end-to-end? Against a real database? With real auth? Calling the real third-party APIs? Did it quietly break something else?
Reading the diff is not enough. Running it locally works if I'm sitting at my desk. Trusting tests works until the thing that matters is not covered by a test.
The loop I wanted was:
- Agent opens a PR.
- CI passes.
- A real, isolated copy of the whole app comes up at its own URL - UI, API, worker, sandbox, database, queue, everything.
- I open that URL on whatever device I have and actually use the feature.
- If it's wrong, I tell the agent what's wrong. If it's right, I merge.
Step 3 is the part that took actual infrastructure work. Everything else was already close.
This post is about step 3.
The app, briefly
Runvault is an agent platform. Users chat with it from a dashboard or a messaging channel, and the agent runs tool calls inside an isolated sandbox.
That means the app has a few moving parts:
- a dashboard SPA for the UI,
- a gateway API for HTTP, webhooks, and SSE,
- an agent worker that consumes jobs and runs the agent loop,
- a sandbox host where the agent's shell actually executes, with persistent per-user storage.
Plus Postgres and Redis.
I run the API and worker on Railway, the sandbox host as a Cloudflare Worker with containers, and the dashboard on Cloudflare Pages.
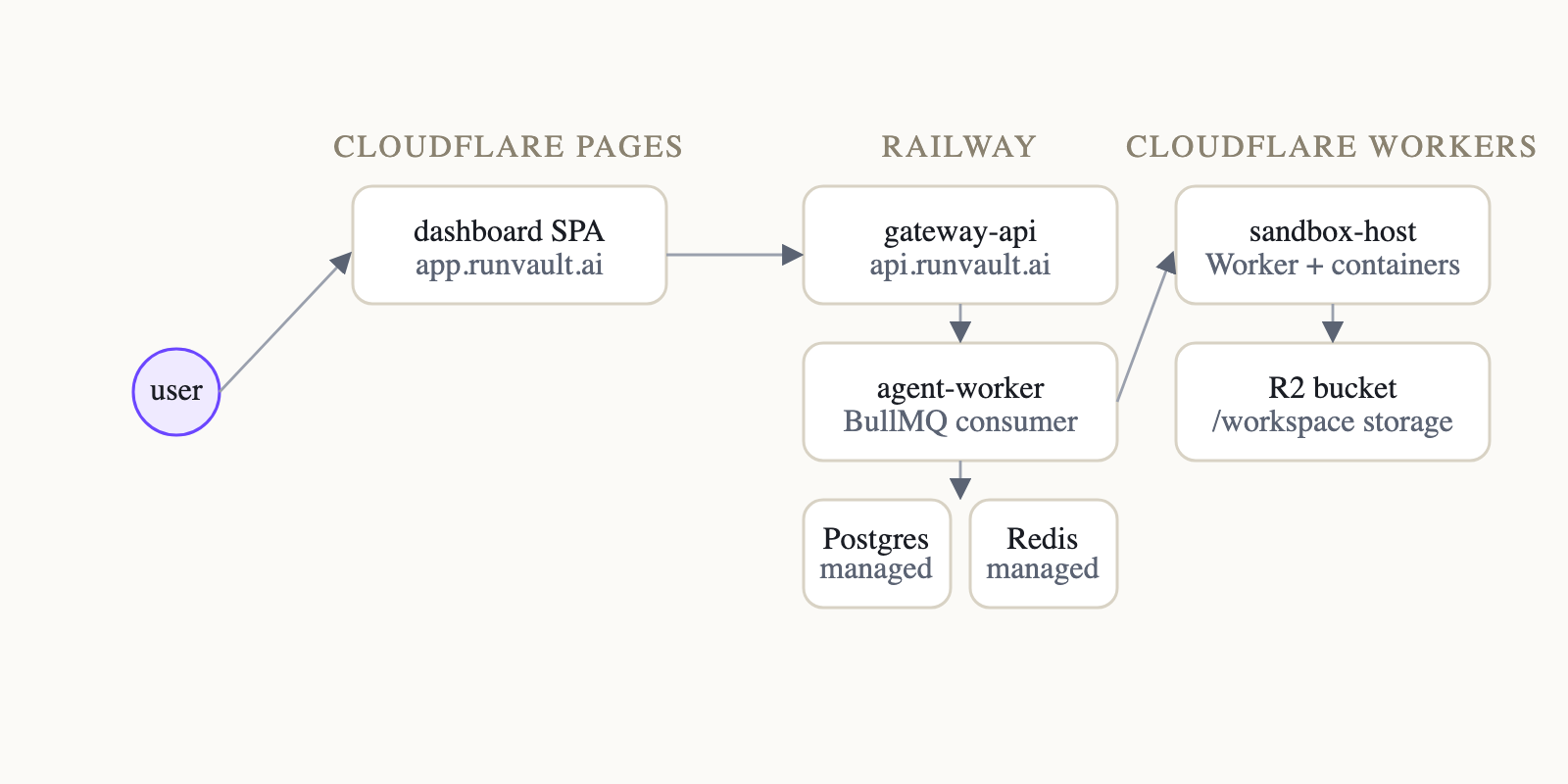
Production topology. The interesting part is not the diagram itself. It's that I wanted this same shape to exist automatically for every PR.
Three environments, one repo
The setup is simple:
- PR previews - one full stack per open pull request, deleted when the PR merges or closes.
- staging - a long-lived environment that tracks the
stagingbranch. - production - tracks
main.
Every PR targets staging.
When a PR merges, Railway and Cloudflare redeploy staging automatically. When I'm ready to ship, I run a GitHub Action that fast-forwards main to a known-good staging commit. That ref update is what triggers production deploys on both platforms.
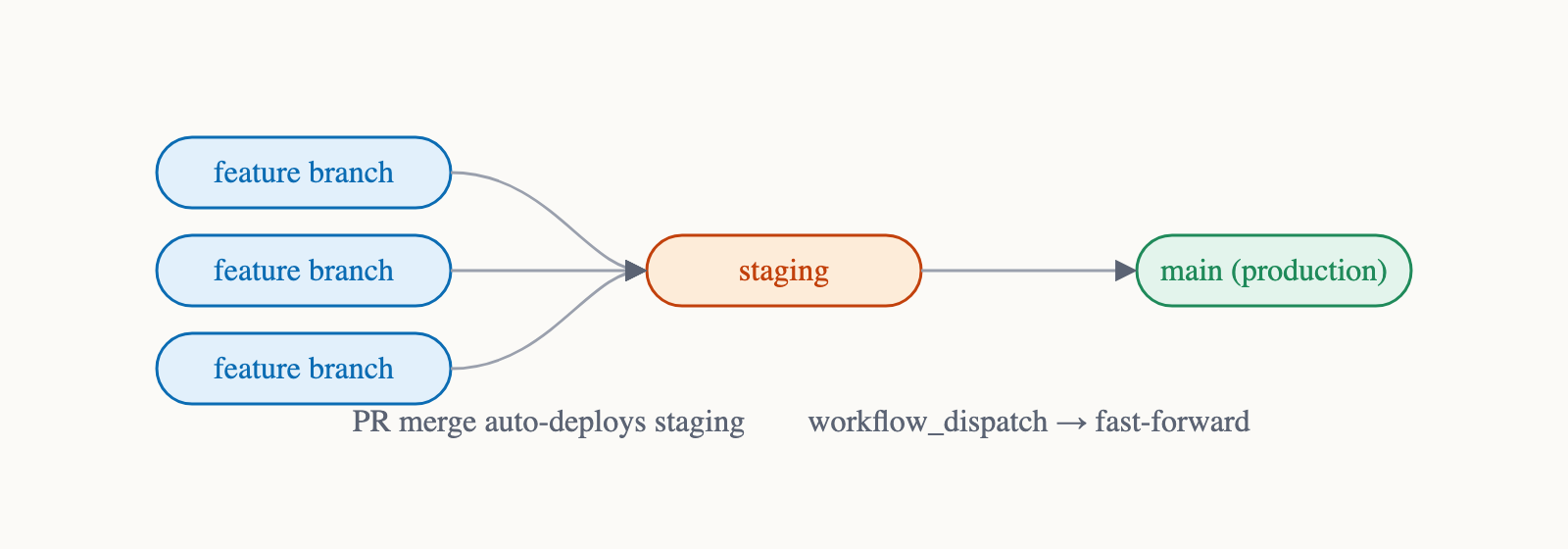
Branches map directly to environments. Promotion is a fast-forward, not a separate deploy system.
The shape is pretty normal. The important part for agent-driven development is that every PR gets a real working URL.
Not a static frontend preview. Not a screenshot bot. Not a mocked backend.
A full stack.
Railway: how PR previews become full stacks
Railway's environments are what made the PR-preview setup manageable.
Each environment gets its own copy of every service, its own Postgres, its own Redis, and its own environment variables. PR preview environments are automatic: open a PR, and Railway spins up a fresh environment named after the PR number, runs the same services, and gives them temporary *.up.railway.app URLs.
That fits the agent workflow really well.
The agent does not need to understand deployments. It pushes a branch and opens a PR. By the time I check it, there is usually already a live URL waiting.
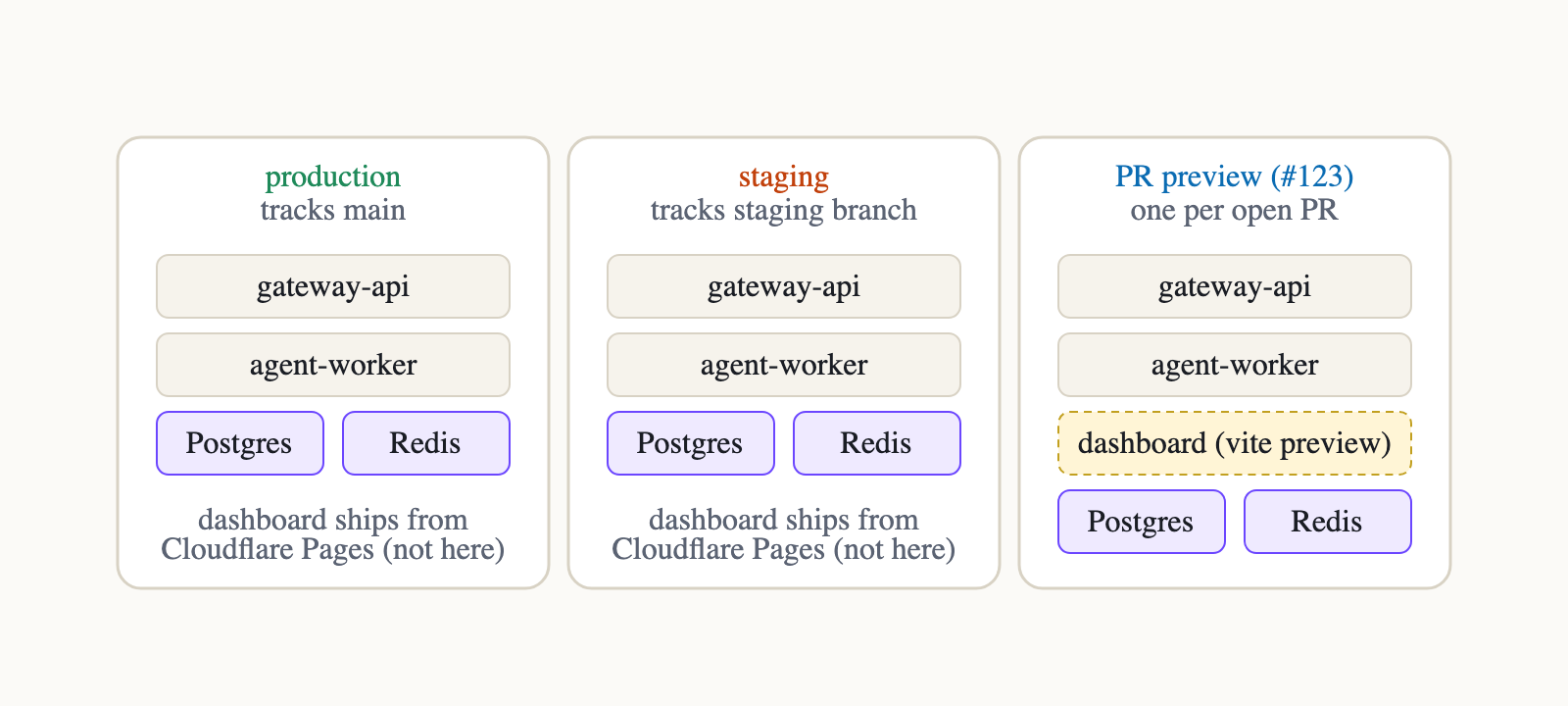
Each Railway environment is a full, isolated stack. Production and staging have two services; PR previews add a third service for the dashboard.
Why the dashboard runs on Railway only for PR previews
In production and staging, the dashboard lives on Cloudflare Pages. Pages is just better for serving an SPA at the edge.
But for PR previews, I need the dashboard to point at that PR's gateway API, not the shared staging API.
Threading a per-PR API URL into a Pages preview build was more friction than it was worth, so I added the dashboard as a third Railway service only in preview environments.
Railway lets one service reference another service's generated domain through a template variable. So the PR-preview dashboard uses:
VITE_API_URL=https://${{gateway.RAILWAY_PUBLIC_DOMAIN}}
Railway fills in the right value for that preview environment.
Open PR #123 and the dashboard at runvault-pr-123.up.railway.app already points to gateway-pr-123.up.railway.app.
No manual config. No extra step for me. No instructions the agent has to remember.
Cookie gotcha worth knowing.
up.railway.appis on the Public Suffix List, likevercel.appandnetlify.app. That means two Railway auto-domains are not considered the same site for cookies, even though they look related. In PR previews, the session cookie needs to beSameSite=None; Secure. In production, where my real domains are same-site, it can beSameSite=Lax. I toggle this based on theRAILWAY_ENVIRONMENT_NAMEvariable Railway injects automatically.
Promotion is a git operation
I intentionally did not build a "deploy to production" button that talks to the Railway API.
Railway already has the behavior I need:
- production watches
main, - staging watches
staging, - PRs create preview environments.
So production promotion is just a git operation.
A small GitHub Action fast-forwards main to a selected staging commit. It has a few safety checks:
- the SHA must be reachable from
origin/staging, origin/mainmust already be an ancestor of it,- CI must have passed on that commit.
The push is protected by a GitHub Environment with required reviewers, so production still needs human approval. But what I'm approving is a git push, not some custom deploy process.
That matters because it works from my phone. I can approve the workflow in the GitHub app and move on.
Cloudflare: a Worker per environment, isolated by R2 prefix
The sandbox host is where the agent's shell tool actually runs.
It's a Cloudflare Worker that owns Durable Objects, one per tenant, and mounts an R2 bucket into each container as /workspace.
Persistent storage, edge-located compute, containers on demand - it's a good fit for this problem.
It's also the part of the system I least want shared between environments.
If one shared Worker breaks, it can kill every in-flight agent run using it. I learned that the hard way.
For a while, I had one sandbox Worker shared by staging and PR previews. Then a PR changed the Worker's internal protocol and broke staging mid-execution. Even worse, PR-preview gateway APIs were seeing staging tenant state because they all pointed at the same R2 prefix.
That completely defeats the point of previews.
If a PR preview can touch staging data, it is not a safe playground anymore. And if I can't trust the preview, the whole "agent opens PR, I test from my phone" loop falls apart.
So I gave every environment its own Worker and isolated each Worker's storage with an R2 prefix.
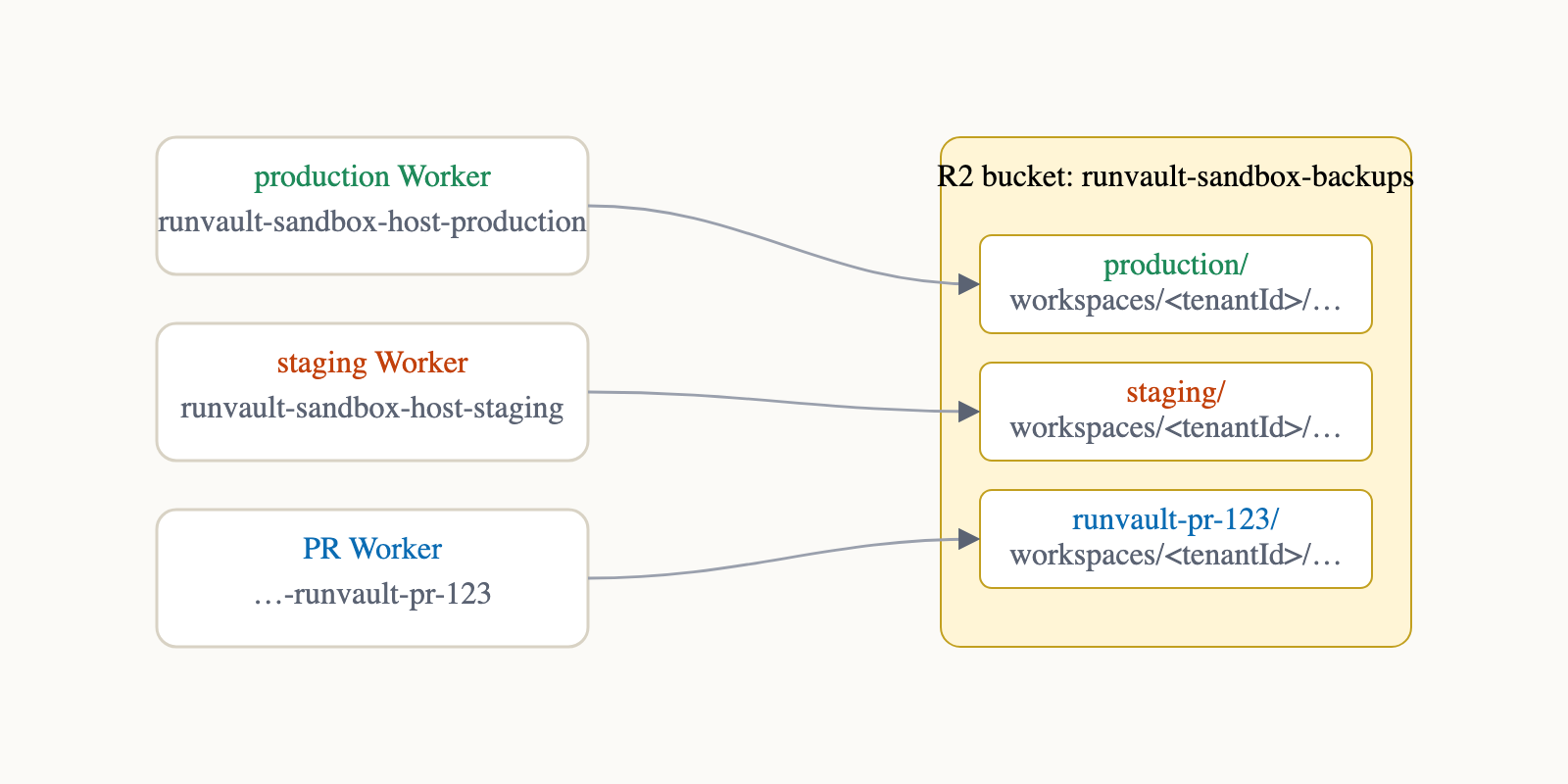
Three Workers, one bucket, three prefixes. Tenant state cannot leak across environments, even if a request gets routed incorrectly during a bug.
How the Railway side finds the right Worker
I expected this part to be annoying, but it ended up being pretty clean.
Each environment's Worker needs a shared secret so Railway can authenticate with it. Railway also needs to know which Worker URL to call.
The obvious version is to have CI write environment-specific values back into Railway. That works, but it creates more glue. It is also exactly the kind of thing that drifts over time.
Instead, both sides derive the same values from the environment name.
The GitHub Action computes:
- Worker name:
runvault-sandbox-host-${ENV_NAME} - Shared secret:
HMAC(master, "sandbox-host:" + ENV_NAME)
The Railway services do the same derivation at runtime using the RAILWAY_ENVIRONMENT_NAME that Railway already injects.
No CI-to-Railway plumbing. No per-environment secret sync. No manual step.
A new PR environment appears, and the values it needs are already derivable.
Pages for the production dashboard
The dashboard on Cloudflare Pages is intentionally boring.
Pages watches the repo, runs:
pnpm install && pnpm --filter dashboard build
Then it serves the built SPA with fallback routing.
VITE_API_URL is set at build time per environment, so the right API origin is baked into the bundle.
Pages handles caching, TLS, and custom domains. There is no GitHub Action for this. Pages just rebuilds when the branch changes.
GitHub Actions: the glue, but only barely
I kept CI/CD small on purpose.
Most of the deployment behavior lives in Railway and Cloudflare. GitHub Actions only does three things:
- CI - install, build, lint, type-check, and test. Runs on every PR and every push to
stagingormain. This is the gate that needs to pass before I trust a preview. - Sandbox-host deploy - the only workflow that actually deploys code. It runs on PR open/sync/close and on pushes to
stagingormain. It resolves the environment name, computes the Worker name and secrets, runswrangler deploy, and cleans up on PR close. - Promote to production - fast-forwards
main, protected by a required-reviewer GitHub Environment.
Things that are not in GitHub Actions:
- Railway deploys,
- Pages deploys,
- Postgres migrations,
- Worker URL plumbing.
Railway watches branches itself. Pages watches branches itself. Migrations run on container start. Worker URLs are derived.
Less glue means fewer things to break.
The cleanup step on PR close is more important than it sounds. When the workflow is "open lots of PRs, throw many of them away," stale resources pile up quickly: Workers, R2 prefixes, Durable Object namespaces, container apps.
Forgetting to clean those up is how a small bill quietly turns into an embarrassing one.
So PR close runs the same workflow in teardown mode: delete the Worker, delete the per-PR R2 prefix, delete the container app, and delete the Durable Object namespace.
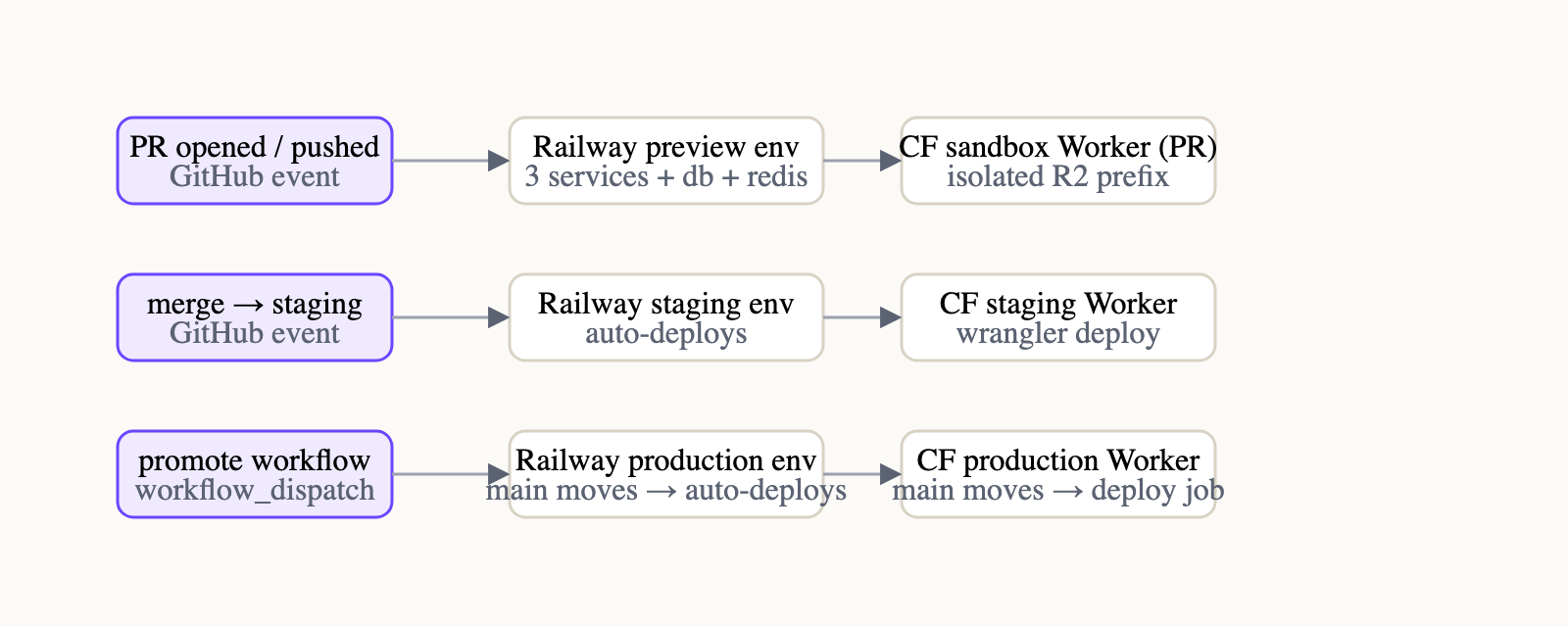
Three event sources, three pairs of outcomes. Each row is one deploy shape.
The loop, in practice
A typical session looks like this:
I'm on a walk, on a train, or out to lunch. An agent finishes something I asked for earlier - maybe a dashboard page, an integrations fix, or a change to how sandbox file uploads work.
It opens a PR.
My phone buzzes when CI passes. Then it buzzes again when the Cloudflare workflow finishes deploying the PR Worker.
I open the PR, tap the Railway preview URL, sign in, and use the feature.
Not a screenshot. Not a fake environment. The real feature, running against a real database, hitting an isolated sandbox Worker that is separate from staging and every other PR.
If something is wrong, I dictate a follow-up to the agent and put my phone away. If it looks good, I approve and merge.
Staging redeploys automatically.
Later, usually the next morning, I run the promote workflow from the GitHub mobile app, approve the protected-environment prompt, and production catches up.
Whole features have landed in this codebase that I never ran on my laptop.
What worked, what I'd do differently
What worked. Letting each platform watch its own branch removed a bunch of fragile deploy orchestration. Deriving per-environment secrets from a master secret plus the environment name removed even more glue. But the biggest win was full per-PR isolation across every tier. Preview environments that share state with staging are a trap. They seem fine until you start opening lots of PRs, and then the trap snaps shut fast.
What I'd do differently. I should have created a per-PR Cloudflare Worker from day one. I shared the staging Worker with previews for a while "to save time," and it cost me more time than it saved. The state leaks and weird bugs were bad, but the real cost was losing trust in the previews. For this kind of workflow, "every environment gets its own copy of the loudest thing" is a much better default than "share it until it breaks."
The thing that surprised me. This infrastructure work was not really about ops. It was about removing the last reason I had to be chained to a laptop. The agents were already doing most of the typing. What I needed was a way to verify their work without being at my desk. Once that was in place, the way I worked changed.